 ATIA
ATIA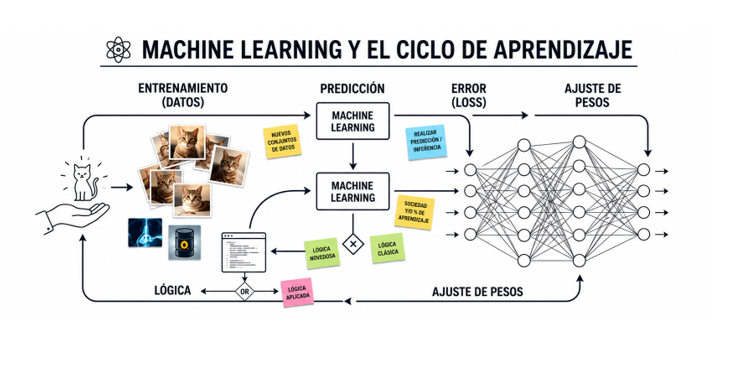
Durante décadas, los ordenadores solo hacían lo que les decíamos. Ahora aprenden solos. Esta es la historia de cómo pasamos de programar instrucciones a entrenar inteligencias.
En el artículo ¿Qué es un algoritmo y cómo funciona? Explicábamos que los algoritmos son una serie de pasos que aplicados sirven para resolver problemas. Hoy damos un salto importante. Porque hay un momento en la historia de la informática que lo cambia todo: ¿y si en lugar de decirle al ordenador exactamente qué hacer, le enseñamos a aprenderlo por sí solo?
Esa pregunta es el origen del machine learning, o aprendizaje automático en español. Y la respuesta a esta pregunta fue la siguiente: si le das a una máquina suficientes ejemplos, y la dejas ajustarse sola basándose en sus errores, acaba aprendiendo a resolver problemas que nadie le programó directamente.
Para entender la diferencia, imagina que quieres enseñar a alguien a reconocer si una foto tiene un gato o no. Con programación clásica, tendrías que definir reglas: “si hay orejas puntiagudas, si el hocico es pequeño, si los ojos son así…”. El problema es que los gatos son infinitamente variados. Cualquier regla que escribas tendrá excepciones. Con machine learning, simplemente le muestras miles de fotos de gatos y miles de fotos que no son gatos, y el sistema aprende solo qué patrón distingue unos de otros.
“El cambio fundamental del machine learning no es que los ordenadores sean más rápidos. Es que dejamos de programarles respuestas y empezamos a enseñarles a encontrarlas.”
1. De dónde viene la idea
El término “machine learning” lo acuñó Arthur Samuel en 1959, un ingeniero de IBM que programó un ordenador para jugar a las damas. Lo interesante no era que el programa jugara: era que aprendía de cada partida y mejoraba solo con el tiempo, hasta superar al propio Samuel.
Pero la idea tardó décadas en volverse práctica, por una razón muy sencilla: necesita datos masivos y potencia de cálculo enorme. Ambas cosas llegaron en los años 2000 y 2010 con internet y los chips modernos. De repente, había millones de imágenes, textos, vídeos y comportamientos digitales disponibles para entrenar sistemas. El machine learning, que llevaba cincuenta años esperando, explotó.
2. Cómo funciona: el ciclo de aprendizaje
El proceso por el que una máquina aprende sigue siempre la misma lógica básica, independientemente de si está reconociendo fotos o prediciendo el precio del petróleo. Son cuatro pasos que se repiten millones de veces:
- Datos de entrenamiento: El sistema recibe ejemplos con sus respuestas correctas. Miles, millones de ejemplos etiquetados: “esta foto es un gato”, “este email es spam”, “este tumor es benigno”.
- Predicción: El modelo intenta dar una respuesta a cada ejemplo. Al principio, se equivoca constantemente.
- Medición del error: Se compara la respuesta del modelo con la correcta y se calcula cuánto se equivocó. A este cálculo se le llama función de pérdida o loss.
- Ajuste: El sistema modifica sus parámetros internos para equivocarse menos la próxima vez. Este ajuste se repite millones de veces hasta que el error es mínimo.
La clave está en ese ajuste continuo. Dentro de cualquier modelo de machine learning hay miles o millones de valores numéricos — llamados pesos o parámetros — que el sistema va modificando poco a poco para mejorar sus predicciones. Es como afinar un instrumento: al principio suena fatal, pero con cada pequeño giro de la clavija, se acerca más a la nota correcta.
3. Los tres tipos principales de aprendizaje
No todas las máquinas aprenden de la misma manera. Según cómo se les presentan los datos y qué tipo de retroalimentación reciben, distinguimos tres grandes familias:
- Supervisado: Aprende con ejemplos etiquetados. Recibe datos ya clasificados y aprende a replicar ese criterio. Detectar spam, diagnosticar imágenes médicas, predecir precios.
- No supervisado: Encuentra patrones sin guía. Recibe datos sin etiquetar y agrupa lo similar por su cuenta. Segmentar clientes, detectar anomalías, comprimir información.
- Por refuerzo: Aprende por prueba y error. Recibe puntos por aciertos y penalizaciones por errores, y busca maximizar su recompensa. Videojuegos, robótica, coches autónomos.
El aprendizaje supervisado es el más usado hoy en la industria, porque es el más predecible y controlable. El aprendizaje por refuerzo es el que ha dado los saltos más espectaculares: fue el que usó DeepMind para crear AlphaGo, el sistema que en 2016 derrotó al campeón mundial del juego de Go, considerado durante décadas invencible para una máquina.
“El aprendizaje por refuerzo no aprende de datos humanos. Aprende de sus propias experiencias, jugando millones de partidas contra sí mismo hasta dominar algo que ningún humano le enseñó.”
4. Redes neuronales: cuando la biología inspira a la informática
Dentro del machine learning hay una familia especial de modelos que merece atención propia: las redes neuronales artificiales. Su nombre no es casualidad — están inspiradas, vagamente, en cómo funciona el cerebro humano.
Nuestro cerebro procesa información a través de neuronas conectadas entre sí. Cuando aprendes algo, algunas conexiones se refuerzan y otras se debilitan. Las redes neuronales artificiales imitan esta estructura: tienen capas de nodos matemáticos conectados, y el aprendizaje consiste en ajustar el peso de esas conexiones.
Cuando una red tiene muchas capas — decenas o cientos de ellas — hablamos de deep learning o aprendizaje profundo. Estas redes son capaces de aprender representaciones increíblemente complejas: no solo “hay una cara en esta foto”, sino “esta cara expresa tristeza” o “esta persona tiene unos 40 años”. Cuanto más profunda la red, más abstracto y sofisticado lo que aprende.
El deep learning es lo que hay detrás de casi todo lo que hoy llamamos IA: el reconocimiento de voz de tu móvil, los filtros de Instagram, los subtítulos automáticos de YouTube, y sí, también los modelos de lenguaje como ChatGPT o Claude, de los que hablaremos próximamente.
5. Lo que el machine learning no es
Hay varios malentendidos comunes que vale la pena desmontar antes de terminar.
- “La IA piensa como nosotros”: No. Reconoce patrones estadísticos en datos. No tiene comprensión, conciencia ni intenciones. Es matemática muy sofisticada, no cognición.
- “Aprende cualquier cosa”: Solo aprende lo que hay en sus datos de entrenamiento. Si esos datos son sesgados, incompletos o erróneos, el modelo aprende esos mismos problemas.
- “Siempre mejora con más datos”: Más datos ayudan, pero los datos de mala calidad pueden empeorar un modelo. La cantidad sin calidad no funciona.
- “Es una caja negra incontrolable”: Algunos modelos son opacos, pero hay toda una disciplina — IA explicable — dedicada a entender y auditar cómo toman decisiones.
Entender estos límites es tan importante como entender las capacidades. El machine learning es una herramienta extraordinariamente poderosa, pero sigue siendo una herramienta. Su valor depende de quién la diseña, con qué datos se entrena y para qué objetivo se usa.
6. El presente y el futuro inmediato
En 2026, el machine learning ya no es una promesa futura: es infraestructura del presente. Los modelos de lenguaje grandes han demostrado que las redes neuronales profundas, entrenadas con suficientes datos y potencia de cálculo, pueden hacer cosas que hace diez años parecían ciencia ficción: escribir código, traducir idiomas en tiempo real, diagnosticar enfermedades raras, componer música o mantener conversaciones coherentes durante horas.
El debate ahora no es si el machine learning es capaz. Es cómo se usa, quién lo controla y qué consecuencias tiene para la sociedad. Esas preguntas — sobre sesgos, transparencia, privacidad y poder — son las que marcarán la agenda tecnológica de los próximos años.
“En el próximo artículo de esta serie entraremos de lleno en los modelos de lenguaje: qué son, cómo funcionan por dentro y por qué saben hablar de casi cualquier cosa.”